A 5 GB Docker Image for a 7.4 MB Model
Optimize your dockers!
I don't typically read my docker logs when they build or start. After designing a system and running it locally in my dev environment I throw the dependencies into their respective files and put it all together with a nice compose file and deploy it. In the past it was coolify, now I just ask my agents to do it.
This one was just another round of changes on updating a storage process, but I decided to watch the process after having a thought of why these deployment require more than a minute or two, from first principles I couldn't imagine it being much more complicated for moving around a few python files. The upper abstractions of observations didn't say much (this was in coolify), just a boring in_progress with no activity and no error until I dove down to the build logs and found them at second 600, still downloading packages
The build was downloading 3.9 GB of NVIDIA CUDA libraries. Not unheard of, but this machine has no GPU. The model being served is 7.4 MB and explicitly runs on CPU.
The model is GMNet, a dual-branch CNN from an ICLR 2025 paper on inverse tone mapping. My service uses it to predict HDR gain maps, runs maybe dozen jobs a day in an async queue, and has no GPU. The model code says so explicitly:
self._device = torch.device('cpu') # Force CPU for compatibilityThe problem is that PyTorch ships its own CUDA runtime as PyPI packages. On linux/amd64, the default torch wheel declares roughly 14 nvidia-*-cu12 packages as dependencies, and pip and uv will install them on any Linux x86_64 machine regardless of whether a GPU is present. A CPU-only wheel index exists at download.pytorch.org/whl/cpu, but you have to opt into it.
Pulling the download sizes from uv.lock for the Linux x86_64 platform:
888 MB torch
707 MB nvidia-cudnn-cu12
594 MB nvidia-cublas-cu12
322 MB nvidia-nccl-cu12
288 MB nvidia-cusparse-cu12
287 MB nvidia-cusparselt-cu12
268 MB nvidia-cusolver-cu12
193 MB nvidia-cufft-cu12
155 MB triton
88 MB nvidia-cuda-nvrtc-cu12Total: about 3.9 GB.
The reason cold builds were so slow is that Coolify rebuilds with --pull on every deploy. When a base image update busts the Docker layer cache, the entire Python environment gets reinstalled from scratch. A cache miss on a 3.9 GB dependency.
What inference actually needs
Before reaching for the obvious fix (the CPU-only wheel index), I wanted to think about whether PyTorch was the right tool for production inference at all.
PyTorch is a training framework. Its two main jobs are tensor math and autograd: tracking gradients through a computation graph so you can run backpropagation. At inference time you call torch.no_grad() to skip the gradient tracking, but all the machinery stays installed. The 888 MB torch wheel and the 3 GB of CUDA it pulls along still exist there on your disk in whatever pip or uv directory you have.
What inference actually needs is something that can run a fixed sequence of matrix operations and return a result. I ended up working with two ideas that I know were lightweight:
- ONNX Runtime. Export the PyTorch model to ONNX format once as a development step, bundle the
.onnxfile, and run production inference with a 20 MB engine that uses MLAS under the hood. No CUDA. - tinygrad. A most lightweight ML framework featuring a lazy graph builder and C-code JIT kernel fusion. It bypasses export workflows entirely by ingesting PyTorch weights natively at runtime.
At first I just tried exporting to ONNX and using tinygrads frontend but it didn't handle DepthToSpace correctly in my testing, which is how PyTorch's PixelShuffle gets serialized, and GMNet uses pixel shuffle in its upsampling tail. Ok, so maybe I will just port GMNet to tinygrad directly instead of going through ONNX, could be interesting.
The tinygrad design is fun, when you write out = conv(x).relu() in PyTorch, that executes immediately: kernels are dispatched, buffers are allocated, results are materialized. In tinygrad, nothing executes. The operation is recorded as a node in a lazy graph. When you call .realize(), the scheduler analyzes the entire graph and compiles it into fused kernels, potentially collapsing a chain of operations into a single compiled function with no intermediate buffer allocations. For a residual block (conv + relu + conv + add), that whole sequence can become one kernel. Take a look at the generated kernel source with DEBUG=4. This itself is not new, I remember building computation graphs with tf.Session() back in when Tensorflow was still a competitor, and torch.compile() has joined us as well.
I guess that wasn't the fun part, it's more-so how it gets there. It is small, modular, gives the low level building blocks and lets you stand it up as you prefer.
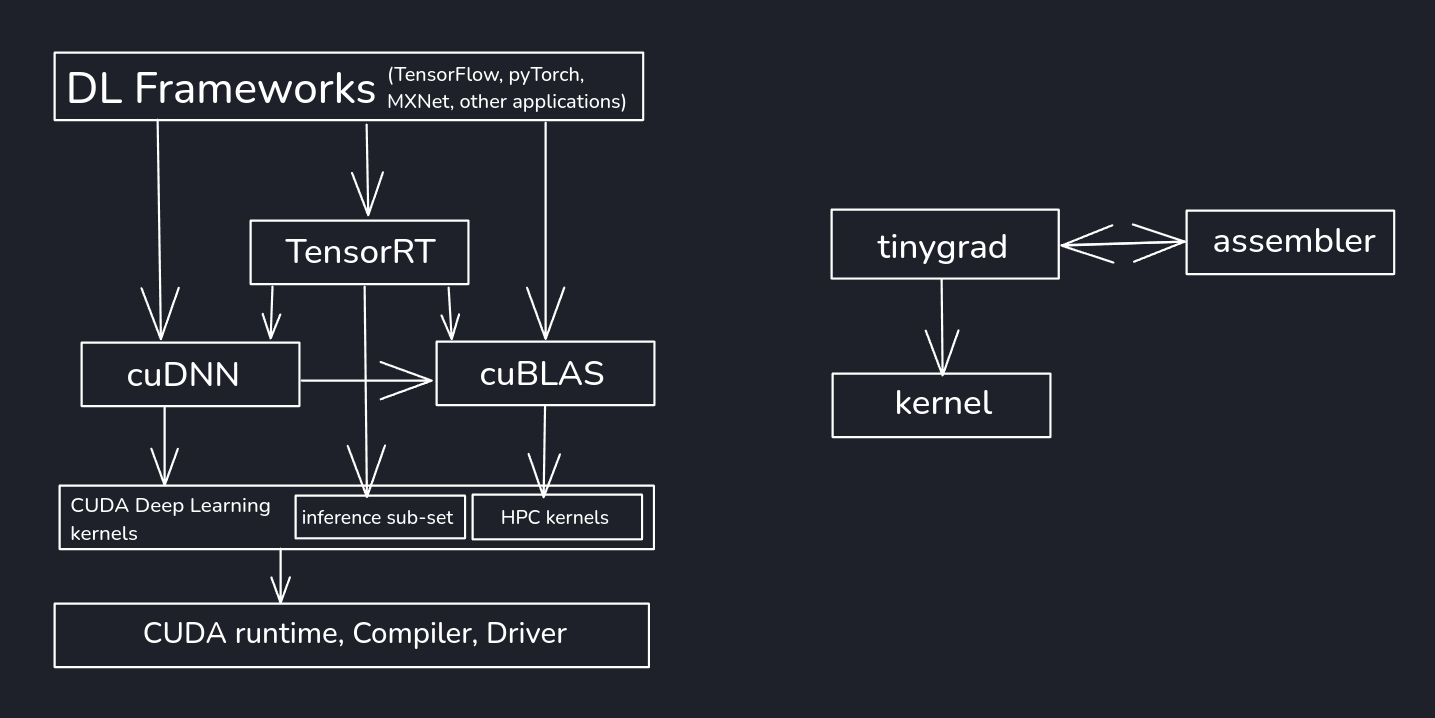
Porting GMNet
The model used, GMNet, is a dual-branch CNN. The global branch processes a 256x256 thumbnail to extract scene-level features. From those, it produces three things: a small 3x3 kernel to be applied dynamically to the local branch, a channel-attention vector, and a scalar called qmax representing the global ceiling on how many stops of HDR boost to allow. The local branch processes the full-resolution image through residual blocks. The two branches interact through a depthwise convolution where the kernel itself was produced by the network, which is an unusual shape: the conv weights are the output of another subnetwork, not fixed parameters. The result gets upsampled with pixel shuffle back to full resolution.
Four things made the port non-trivial.
AdaptiveAvgPool2d with non-integer ratios
GMNet uses AdaptiveAvgPool2d to pool feature maps to (3,3) and (1,1). The obvious tinygrad implementation is reshape-plus-mean, which works when input dimensions divide evenly by output dimensions. For the (3,3) case, the global branch feature map is 64x64 (256x256 thumbnail, downsampled 4x). 64 divided by 3 is not an integer.
PyTorch's AdaptiveAvgPool2d handles non-integer ratios with a floor-start, ceil-end formula: start = (i * in) // out, end = ((i+1) * in + out - 1) // out. For 64 to 3, this produces bins [0:22], [21:43], [42:64], where adjacent bins overlap by one element each. The reshape-and-mean approach gives uniform 21-element bins with no overlap. Getting this wrong cost 50 dB of PSNR before I found it. The fix is explicit slice-and-mean for each output cell:
rows = []
for i in range(output_size):
sh = (i * H) // output_size
eh = ((i + 1) * H + output_size - 1) // output_size
cols = []
for j in range(output_size):
sw = (j * W) // output_size
ew = ((j + 1) * W + output_size - 1) // output_size
cols.append(x[:, :, sh:eh, sw:ew].mean(axis=(2, 3), keepdim=True))
rows.append(Tensor.cat(*cols, dim=3))
return Tensor.cat(*rows, dim=2)PixelShuffle: CRD not DCR
ONNX's DepthToSpace operator has two modes: DCR (the default) and CRD. PyTorch's PixelShuffle uses CRD. The correct reshape-and-permute sequence:
def pixel_shuffle(x, r=2):
N, C4, H, W = x.shape
C = C4 // (r * r)
x = x.reshape(N, C, r, r, H, W)
x = x.permute(0, 1, 4, 2, 5, 3)
return x.reshape(N, C, H*r, W*r)Getting this backwards (DCR order) produces outputs that look plausible but are spatially scrambled.
Weight key matching
tinygrad's load_state_dict uses list indices as key components. PyTorch's nn.Sequential numbers all children including parameter-free ones like ReLU (index 1, 3, 5). To match keys like conv.0.weight, conv.2.weight, conv.4.weight, the tinygrad list needs None entries at the skipped positions:
class DownConv:
def __init__(self, in_c, out_c):
self.conv = [
Conv2d(in_c, out_c, 3, stride=2, padding=1), # index 0
None, # index 1 (ReLU, no params)
Conv2d(out_c, out_c, 3, padding=1), # index 2
None, # index 3
Conv2d(out_c, out_c, 3, padding=1), # index 4
None, # index 5
]All 126 weight keys matched on first load once this was in place.
The dynamic kernel and lazy fusion
GMNet's depthwise convolution uses a kernel computed at inference time from the global branch. In tinygrad this creates a data dependency between two parts of the graph, and the lazy scheduler can fuse the kernel computation into the convolution's inner loop, recomputing it for each input position rather than once. ok just call .realize() on the kernel before passing it to the convolution.
kernel_dw = kernel.reshape(C, 1, 3, 3).realize()
mask = x.conv2d(kernel_dw, padding=1, groups=C)Proving it correct
No errors does not mean no errors. You only know you have not erred when the outputs are provably the same so I built a verification suite: four synthetic test cases (gradient, checkerboard, portrait-ratio, landscape-ratio) run through the PyTorch reference implementation, stored as .npz golden files.
- Numerical equivalence:
assert_allclosewithatol=1e-3on raw output tensors - PSNR above 70 dB versus the golden (above 80 is effectively identical)
- SSIM above 0.999 with gaussian weights
- Output invariants: correct shape, values in range, non-degenerate
- qmax equivalence: the second model output also within tolerance
In CI, a GitHub Actions workflow regenerates the goldens from PyTorch on every pull request that touches the model files, then runs the full suite. Missing goldens or a broken import are hard failures.
Final numbers after all correctness fixes:
PSNR: 120.6 dB
SSIM: 1.000000
Max|err|: 0.0000035 per pixelAt 120 dB PSNR, the 8-bit JPEG outputs are bit-for-bit identical between the two implementations. The AdaptiveAvgPool fix was responsible for almost all of that gap: without it the PSNR was around 70 dB, with it it jumped to 120.
The benchmark
Dependency size on Linux x86_64:
| Runtime | Download | Installed |
|---|---|---|
| PyTorch + CUDA | 3,915 MB | ~5 GB |
| tinygrad | 1.8 MB | 14 MB |
Inference latency on the production machine (i9 CPU, Linux x86_64):
| Image size | PyTorch | tinygrad |
|---|---|---|
| 256x256 | 157 ms | 744 ms |
| 512x512 | 797 ms | 2,220 ms |
| 1024x768 | 2,555 ms | 6,686 ms |
Well ok, the torch variant used oneDNN, which JIT-generates ISA-specific SIMD convolution kernels for the host CPU. tinygrad generates competent but generic clang code. For a CNN on x86 it was roughly 3 to 4 times slower across image sizes.
So I ended up just keeping it simple and exporting the model to ONNX rather than the full tinygrad port. For a CPU inference workload where latency matters even a little, oneDNN is the right call and ONNX Runtime gets you there with a 20 MB dependency.
The point
The concise version of what changed: before, every deploy downloaded 3.9 GB of NVIDIA CUDA libraries for a machine with no GPU, because I had used torch as a production dependency when it was only needed for model loading. After, the runtime dependency is ONNX Runtime (20 MB). Cold builds take two minutes and Base-image cache misses are free again.