Measuring LLM Sensitivity: What Actually Moves the Output
This is the second of three posts. The first one, Nearby Prompts, Distant Trajectories, lays out the framing: why chaos vocabulary (fixed points, attractors, Lyapunov exponents, edge of chaos) is a useful way to think about what happens when a small input change produces a big output change in a language model. If you haven't read it and you want context for why any of this matters, start there. The third post, Where the Branch Commits, picks the thread up inside the network, by asking whether the branch flip is causally localizable to a specific residual-stream position.
This post is the experiment. What I actually measured, how I measured it, what moved, what didn't, and the ways the measurement itself tried to lie to me. I ran about 21 models, a ladder of tiny prompt perturbations, deterministic decode, a stack of metrics, and I want to walk through the findings roughly in the order I was surprised by them.
Fair warning: the most important conclusions in this post are about the measurement, not about the models. Short-output stability of reasoning models is mostly a metric artifact. Low perturbation distance can be a model that's quietly stopped responding, not a stable one. Confident prompt-end logits do not mean a stable trajectory. The point of this work isn't to rank models, it's to name failure modes of stability probes before the field starts quoting numbers from them.
The setup
I wanted to cover a meaningful slice of modern open-weight models, plus a handful of legacy models for era comparison.
The current-generation panel is roughly: Qwen 3.5 at 0.8B, 2B, 4B, and 9B; Gemma 2B and 4B in base and instruct flavors; Phi-4, including Phi-4 reasoning+; DeepSeek-R1 (Qwen 7B distilled); Mistral 7B v0.3; Granite; Falcon; SmolLM3 at 3B; OLMo 2 7B; OLMo 3 7B.
The legacy panel is GPT-2 XL, GPT-J, Pythia, OPT, and LLaMA-1 7B. These aren't there as competitive comparisons, they're there because I wanted a reference for "what does a pre-instruction-tuning era model look like on this probe."
All models run with deterministic decode, do_sample=False. Pinned HuggingFace revisions. bf16 weights. Chat templates handled explicitly per model, because the template is part of the input and can absolutely change the tokens the model sees (more on that later, it's a whole mess). No RAG. No tools. Single-turn prompting.
The prompt ladder has seven rungs, from tightest control to loosest:
- Identical prompt. Same string, twice. Should produce zero divergence under deterministic decode. It does. This is the zero-signal control that tells you the probe is clean.
- No-op formatting. Trailing space, leading newline, invisible unicode normalization artifacts. Some of these get erased by the chat template before they reach the model.
- Punctuation. Duplicating a period, swapping a comma for a semicolon, adding parentheses around a word.
- Synonym swap. One word exchanged for a near-equivalent.
- Paraphrase. Same meaning, different phrasing.
- Small semantic change. A minor but real shift in what's being asked.
- Positive control. A meaning-flipping edit (negation, complete topic change). Should produce huge divergence. It always does. If it didn't, something is broken.
The primary metric is sentence-embedding cosine distance between the two output strings. The supporting metrics are Levenshtein token edit distance (for path-level shape), final-layer hidden-state distance for the emitted outputs, and Jensen-Shannon and KL divergences on the next-token distribution at the prompt-end position. No metric is ground truth. They disagree in interesting ways, which is part of the finding.
Sample sizes: 9 prompt pairs per cell in the main panel, 24 pairs in a "hardened" Qwen wave where I wanted tighter statistics on the within-family contrast. Bootstrap CIs, paired permutation tests. I report cluster memberships, not ranks, because the within-cluster ordering is not reliable at these n's.
Okay. That's the machine. Here's what it spat out.
What actually matters is more structured than you'd think
My original plan was to do this at the character level. Just sweep every single-character edit I could think of, across every model, and see which characters move things. I made a chart. It looked great. It was mostly broken, and I want to own that up front because it's the slide where I walk back a previous result.
The problem: a lot of the character-level edits I was making produced strings that, once wrapped in the chat template and tokenized, were byte-identical at the token level. Two different-looking strings, same token IDs going into the model. The model had no way to distinguish them. Green cells (low divergence) were often not the model being robust, they were the template and tokenizer normalizing my edit before the model saw it. I was measuring tokenizer behavior, not model behavior.
A concrete example of the bug: take a prompt "Write a palindrome function." and add a leading space to get " Write a palindrome function.". Two obviously different strings. Run them through a typical chat template, which wraps the user content in <|user|>\n{content}\n<|end|> style markup and strips edge whitespace from the inside, and the resulting token sequences are identical. The model sees one input. My "edit" produced a 0.00 divergence, and I had a green cell. That's not the model being robust. That's the template erasing the edit. The character-level sweep was full of cases like that, especially for edge whitespace, and some punctuation at prompt boundaries.
I threw that chart out. What's in the current chart is the token-audited subset: every prompt pair shown actually produced different token IDs after the template. The model saw different inputs. The signal is real.
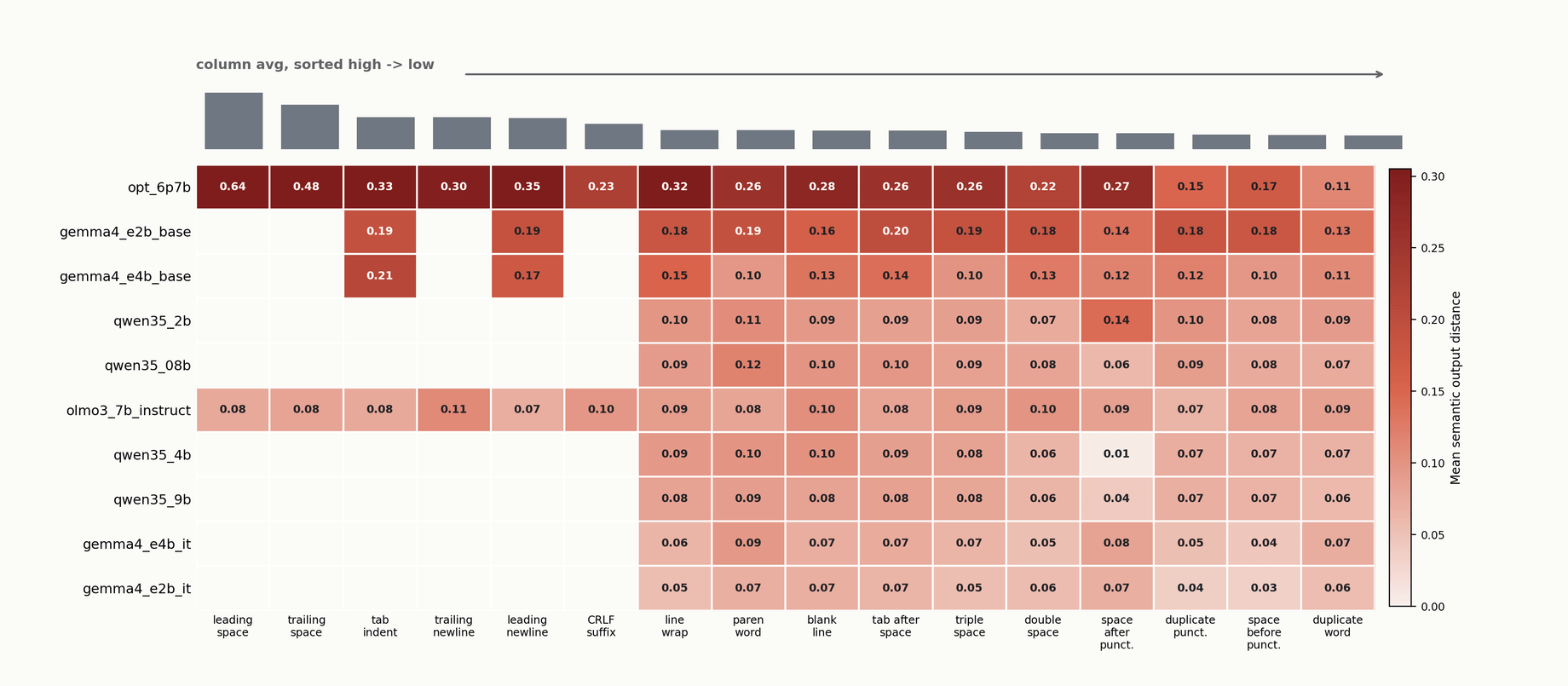
The surprising thing about this chart isn't the columns. It's the rows. The column sort (edit categories, ranked by average effect) is noisy: on average, internal structural edits (line breaks inside a sentence, duplicated punctuation, parenthesizing one word, internal whitespace) produce more divergence than other categories. But column-level ordering isn't stable across models. What is stable is that some models are much more sensitive than others to the same edit set.
Edits that survive tokenization and move outputs tend to be what I'd call structural: things that change the shape of the token sequence even though they don't change what a human reader takes away. Inserting a newline mid-sentence, wrapping a word in parentheses, duplicating a period. Not random bytes. Not leading whitespace at the very edges of the prompt, because the chat template often strips that.
The headline I'd take from this chart is: it is not "any byte flips the model." It's more structured than that. Some edits never reach the model as distinct input. Some survive the template, change tokens, and are enough to steer the model into a different basin. And the question of which models are sensitive to which category of edit is a real question, with a real answer that depends on the model.
One caveat I can't cleanly get out of: tokenizer differences across models are part of what I'm measuring. Two models with different tokenizers will have different edits survive to them, and it's hard to separate "this model is sensitive to this edit" from "this model's tokenizer happens to expose more edits than another's." That's a real limitation, and a research direction for someone.
Same-looking prompt, different trajectory
There's a different kind of chart I want to show that makes the dynamical-systems framing concrete. Instead of averaging output divergence into a single number, you can look at the token-by-token path itself.
For a given prompt pair, run both prompts, generate token by token, and at each generation step compute the Levenshtein distance between the two token prefixes. Plot that distance over time.
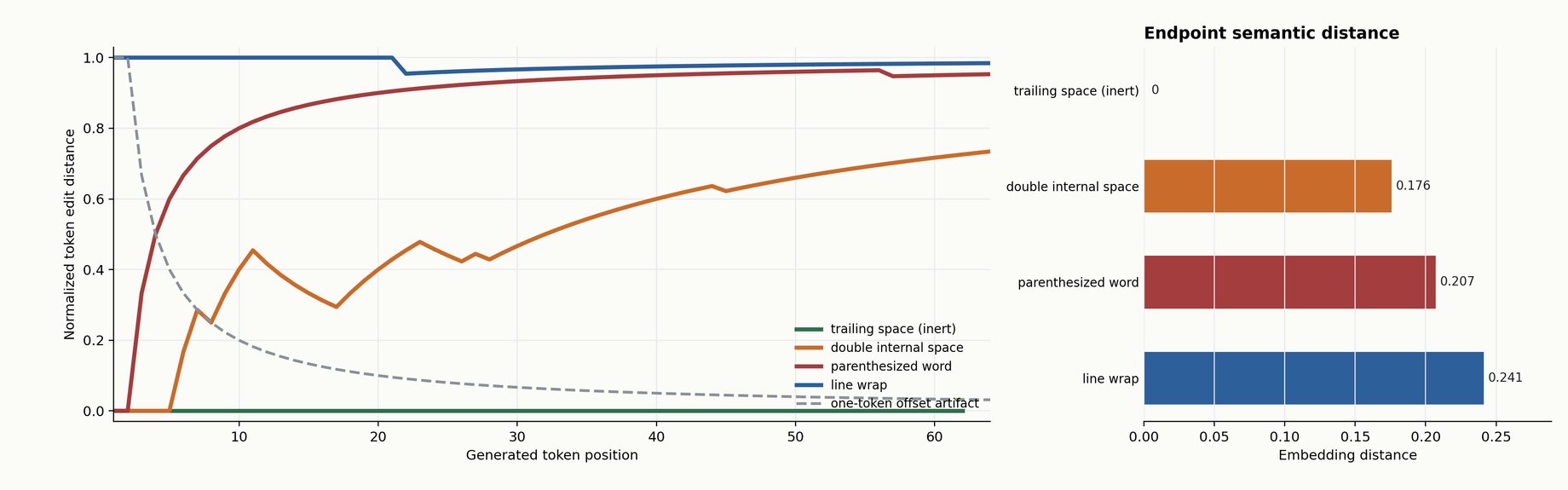
y = 0 means the prefixes are token-identical. A curve staying above zero means the paths genuinely diverged, not just shifted by one token.If y equals zero, the generated token sequences are identical so far. If y is rising, more edits are needed to align them. I use Levenshtein specifically because it's robust to simple insertions: if the problem were "same output, shifted by one token," Levenshtein would eat that and return near-zero. The dashed reference line on charts like this shows what "trivial shift" looks like. The real trajectories stay high, meaning the paths actually diverged, not just shifted.
This is a token-path diagnostic. It's not a semantic claim. Two outputs that diverge in token space might still be semantically close (both defensible answers, just phrased differently), or they might not. That's what the sentence-embedding metric is for.
Here's the demo version of the same idea, where you can watch the branching happen.
Within Qwen, one clean contrast
The cleanest within-family comparison in the dataset is Qwen 3.5, running 0.8B, 2B, 4B, and 9B at 24 prompt pairs each.
0.8B is meaningfully more sensitive than 4B, p < 0.001. 2B also separates from 4B, p = 0.012. So inside one family, with one tokenizer, one training recipe, one set of hyperparameters varying only by size, the smaller models are more sensitive on this probe.
I want to be careful here. 4B versus 9B is indistinguishable at this sample size, p = 0.78. They're clustered together. I am not claiming bigger equals stable. I'm saying that within Qwen 3.5, below some size, sensitivity goes up. Whether that's a scaling law or a peculiarity of the 0.8B training run, I cannot tell you.
There's also a caveat I owe you on this contrast. Qwen 4B and 9B emit a "Thinking Process:" preamble before answering. 0.8B and 2B don't. The preamble is a scaffold, and scaffolds do something to these measurements that I didn't catch at first.
Scaffold stability is mostly a metric artifact
This is the self-audit section, where I walk back something I was briefly excited about.
Here's the short version so I don't accidentally leave the wrong number in your head: at 64 tokens of output, scaffolded models looked about four times more stable than non-scaffolded models. That number is real, and it's also almost entirely an artifact of the metric, not a property of the models. The rest of this section is why.
The long version. At 64 tokens of output, scaffolded models (the ones that start every answer with a <think> block, or "Thinking Process:", or some other deterministic preamble) looked about four times more stable than non-scaffolded models on the sentence-embedding divergence metric. I ran with that result for a few days. It felt like a finding.
Then I actually looked at what the metric was measuring.
Sentence embeddings of short outputs are dominated by the content of those outputs. If the first 40 tokens of the output are an identical <think> preamble across every prompt, then any two outputs on any two prompts share 40 tokens of common content before the actual answer even begins. The embedding sees mostly the preamble. The divergence looks small. But the answer, the part after the preamble, hasn't started yet, or has only barely started.
So "scaffolded models are more stable at 64 tokens" is really "sentence embeddings are dominated by scaffold content when the scaffold is longer than the answer." That's a warning about the metric, not a property of the models.
The fix is to push output length. At 512 tokens, the scaffold is a smaller fraction of the embedded content, and the actual answer dominates. When I do that, the picture shifts a lot.
Here are the 512-token numbers for the scaffolded models:
- DeepSeek-R1 7B: 0.027. Genuinely stable.
- Qwen 4B: 0.050.
- Qwen 9B: 0.057.
- SmolLM3 3B: 0.080. Middle of the pack.
- Phi-4 reasoning+: 0.160.
Phi-4 reasoning+ at 512 tokens is more brittle than GPT-2 XL. Let that sit for a second. A 2024 reasoning model with a <think> scaffold, on a text divergence metric at 512 tokens of output, is less stable than a 2019 base model with no scaffold at all. Scaffold does not equal stable. The headline out of this section is narrow and worth saying cleanly: short-output stability of scaffolded models is mostly a metric artifact. Push output past the scaffold and the artifact goes away. I'm going to come back to Phi-4 in a minute, because its dissociation is the sharpest one in the panel.
Thinking-off, as a separate question
A different question lives nearby, and I want to keep it separate because it's easy to conflate. Once we've ruled out the metric artifact, does the scaffold itself stabilize trajectories? That is: if I turn the <think> block off and score the same prompt pairs at 512 tokens, does divergence go up (the scaffold was helping) or down (the scaffold was hurting)?
I ran that control on Qwen, enable_thinking=False. The effect is not monotonic across sizes.
- Qwen 4B: 0.050 → 0.067 with thinking off. Scaffold helps, about 25%.
- Qwen 9B: 0.057 → 0.072 with thinking off. Scaffold helps, about 20%.
- Qwen 2B: 0.075 → 0.072 with thinking off. A wash.
- Qwen 0.8B: 0.103 → 0.079 with thinking off. Scaffold hurts.
For the bigger Qwens, the scaffold is a mild stabilizer. For 0.8B, the scaffold is itself wobbly enough that turning it off actually reduces divergence. The preamble at small sizes is less deterministic, more prompt-dependent, and it brings its own variance along for the ride. So the effect of "add a <think> scaffold to your model" is size and recipe dependent, not a universal win.
The combined conclusion, putting the artifact question and the mechanism question together: "reasoning models are more stable" doesn't hold as a law. DeepSeek-R1 7B really is stable at 512 tokens, credit where due. Phi-4 reasoning+ really isn't. The scaffold is a factor, but it's neither a guarantee of stability nor a reliable artifact of one.
Era doesn't predict sensitivity
I was also curious whether newer models are systematically more stable than older ones. The intuition would be something like: modern instruction tuning, RLHF, better data, should produce more stable response functions.
The intuition was wrong, or at least a lot noisier than I expected. Here's the cross-family 512-token picture, scaffold-free models only, from the bootstrap readout:
- LLaMA-1 7B: 0.053. A 2023 base model. Cleanly in the stable cluster.
- Gemma E2B instruct: 0.056.
- Mistral 7B v0.3: 0.068.
- Gemma E4B instruct: 0.072.
- Gemma E4B base: 0.119. The base version is much less stable than the instruct.
- Gemma E2B base: 0.199. Same story, even sharper.
- Legacy base models (GPT-2 XL, OPT, Pythia, GPT-J): 0.14 to 0.22.
The LLaMA-1 result surprised me. A 2023 base model, no instruction tuning in the original Meta release, sitting in the stable cluster on my probe at 512 tokens. Candidates I can't rule out for why: its tokenizer happens to expose fewer of my perturbations than newer tokenizers do; its pretraining corpus makes the token distribution unusually flat in the regions my prompts touch; what I'm looking at is an artifact of the community-converted weights commonly used with that model. I ran what checks I could and it held up. I don't want to over-interpret one data point, but I want to leave it on the table for someone with more compute to chase.
The more solid finding in this same chart, and honestly the most robust result in the whole study, is the Gemma instruct-versus-base gap. At 2B: instruct 0.056, base 0.199. At 4B: instruct 0.072, base 0.119. Same family, same size, same architecture. The only difference is the post-training recipe, and the effect is enormous. At 2B the base model is nearly four times more sensitive than its instruction-tuned sibling on the exact same prompt ladder.
That's the cleanest argument in this data for "recipe over calendar." The era a model was released in tells you little. The post-training recipe tells you a lot. Instruction tuning does more than sharpen the model's conversational manners; it narrows the response function enough that small prompt changes stop sliding the output across the manifold quite so freely. That tracks with the intuition that base models live closer to "any prefix could continue any which way," whereas instruction-tuned models have been shaped to route nearby prompts toward nearby answers. The size of the effect, though, was bigger than I expected before I ran it.
The safer narrower claim I'd make about the era question overall is this: older models are not uniformly less sensitive than newer ones on this probe. LLaMA-1 is an existence proof for the failure of a naive era law. The instruct-vs-base gap is the real structural driver. Within that, newer calendars haven't bought us obvious stability at the output-text level.
Also worth naming: token edit distance gives a different ordering than sentence-embedding distance. Metrics disagree. A model that's stable on one might not be on another. No single measurement is safe.
Stability and responsiveness are different things
This is the most principled point I want to make, and I walked into it almost by accident.
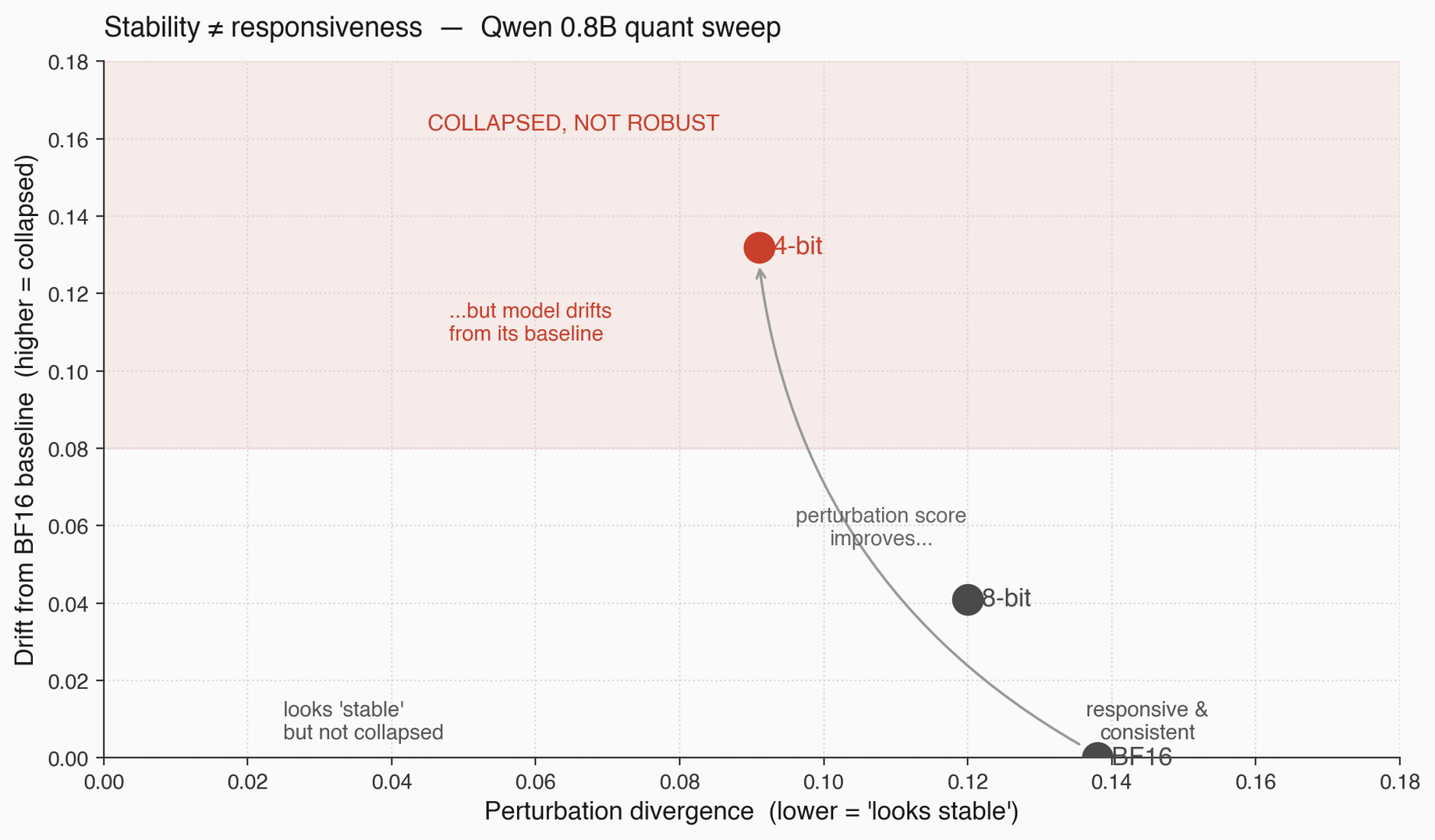
I ran a quantization sweep on Qwen 0.8B. BF16, 8-bit, 4-bit. For each quant, I measured perturbation divergence on the same prompt ladder. At 4-bit, the perturbation divergence dropped from 0.138 (BF16) to 0.091 (4-bit). If I'd only looked at that number, I'd have called 4-bit "more stable" and shipped it.
Then I ran the drift check. Same model, 4-bit, on the same prompts as the BF16 reference. How far did the outputs move, just from quantization, with no prompt perturbation at all? 0.132. Huge.
So the 4-bit model's outputs on identical prompts are 0.132 away from the BF16 reference. And on perturbed prompts, the 4-bit model moves another 0.091 from its own baseline. The model is already far from BF16, and it's not moving much further under perturbation.
That is not robustness. That is collapse. The model has moved onto a narrower output manifold: it's less responsive to input changes, not more stable in any useful sense. If I had a model that output "the the the" forever, regardless of prompt, its perturbation divergence would be zero. It would also be useless. Low perturbation distance with high baseline drift is collapse wearing a stability costume.

The fix is operational, and practically it's what I'd most want you to walk away with. Whenever you measure stability, you have to measure it on two axes:
- Perturbation distance. How much the output moves when the prompt changes slightly.
- Baseline drift. How much the output moves when nothing about the prompt changes but some system variable does (quantization, kernel version, framework update, LoRA swap).
A genuinely stable model has low perturbation distance and low baseline drift. A collapsed model has low perturbation distance because it's stopped responding meaningfully. A responsive model may have higher perturbation distance because it's actually differentiating across meaningful changes in the prompt, and that's fine. Report both axes, or you can't tell the three apart.
I should also be honest about the Qwen 0.8B quant case specifically. The sample size is small, n = 9 prompt pairs per cell, and the within-system flip test is p = 0.19. I am using this case as an existence example of the confound, not as a verdict on 4-bit quantization broadly. The point is principled: any one-axis stability metric will confuse collapse with robustness. Qwen 0.8B at 4-bit is just where I caught it.
Quantize freely. Measure what you're buying.
Boundary beats bulk
If you take one thing from the measurement side of this work, I'd take this. It's the conceptual claim I think most deserves surviving the data wobbles, and it's organized around the sharpest dissociation in the dataset. It is a claim about what to look for, not a fully-proven mechanism. I want to set up the vocabulary first, then lay out the Phi-4 case and what it does and doesn't show.
Mechanism first. The logit vector at a given generation step defines a distribution over vocabulary. Call its bulk the whole distribution, the full mass over all tokens. Call its boundary the margin between the top-1 and top-2 logits: how confident the argmax is about winning.
Bulk and boundary move somewhat independently. The whole distribution can barely move (low JS divergence between original and perturbed prompts) and still have a razor-thin boundary between top-1 and top-2, waiting for any small perturbation to flip the argmax. Conversely, you can shove a lot of mass around and still have such a high-margin top-1 that the argmax doesn't flip.
For autoregressive generation, what matters is whether the top-1 flips. Because if top-1 flips on any single step, the output token is different, the prefix for every subsequent forward pass is different, and the generation runs on a different context from there forward. One flip, autoregression does the rest. The boundary is the fragile point, not the bulk.
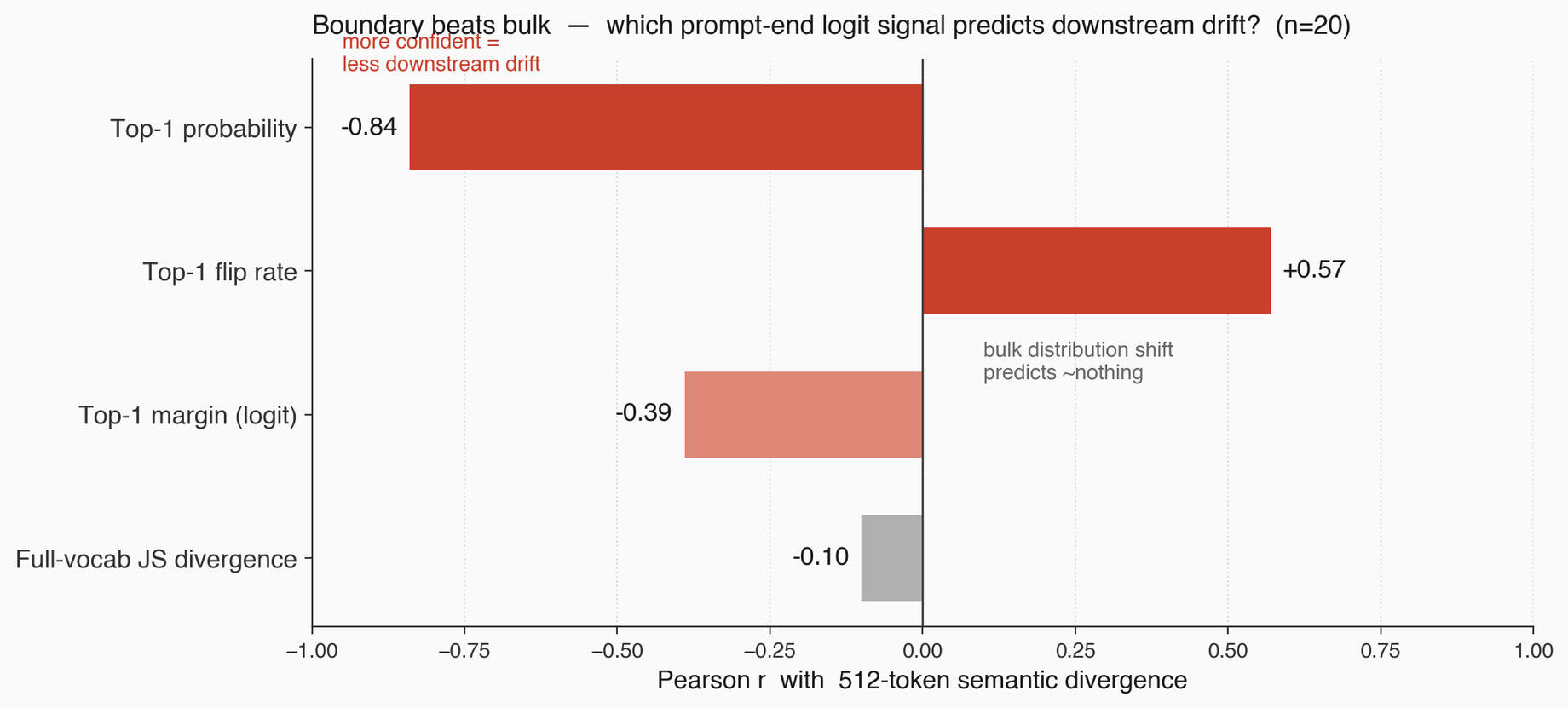
Here's the Phi-4 case, which I want you to remember because it's the cleanest counterexample to "sharp logits mean stable output" that I have.
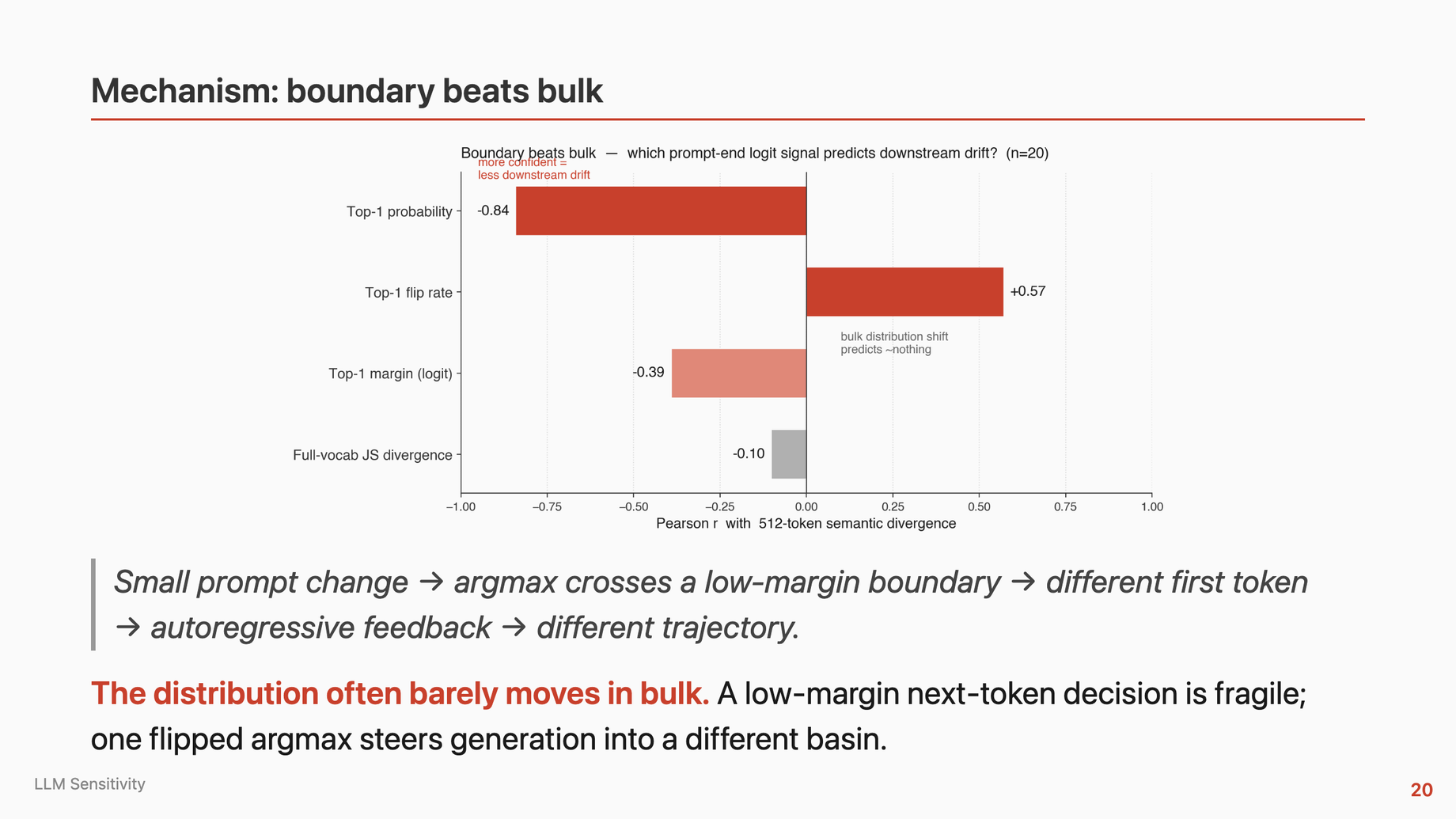
| Metric | Phi-4 reasoning+ | What it means |
|---|---|---|
| Top-1 probability at prompt end | 0.99999996 | Most confident model in the panel |
| JS divergence at prompt end | 1.4 × 10⁻⁹ | Bulk distribution is essentially unchanged |
| 512-token semantic divergence | 0.160 | Second-most brittle in the panel |
| Compare: GPT-2 XL at 512 tokens | 0.144 | Phi-4 is more brittle than a 2019 base model |
Read those four rows together. At the prompt end, the bulk distribution is essentially frozen and the top-1 is effectively certain. No visible instability at position one. And yet over 512 tokens of output, the model diverges more than GPT-2 XL. What that demonstrates cleanly is a single narrow claim: prompt-end confidence does not imply trajectory stability. The weaker version of the claim is certain; the stronger version ("boundary beats bulk right here, at the position we measured") I can't make from these numbers alone.
There are several stories consistent with the four rows. One: somewhere deeper in the generation, a low-margin decision flipped and the autoregressive amplifier carried the two trajectories apart. That's the boundary-beats-bulk reading, and it's the one I lean toward, but it's a hypothesis about a decision I didn't directly observe. Two: the model's accumulation of small distributional differences across many high-confidence-but-not-identical steps eventually diverges even without a single dramatic flip, in which case "bulk that moves a little, repeatedly, across many steps" is the driver and my framing understates the role of bulk. Three: the whole thing is a metric artifact (register shift, formatting drift, sentence-embedding weirdness), in which case the cleanest response is to pair this probe with a per-step margin trace before leaning too hard on a mechanistic claim. I think story one is likeliest. But I have to keep the other two on the table.
A mechanism story for Phi-4 specifically, which I want to label as speculation because I haven't traced it directly: Phi-4's <think> tag frequently fails to close in my runs. The model ends up in a kind of repetition loop inside the scaffold, and inside that loop there are plausibly low-margin boundary decisions that don't exist at the prompt end. A small prompt perturbation flips one, and from there the trajectory is different. I'm confident in the dissociation (the numbers are the numbers), but I am not yet claiming I've proven the mechanism. The per-step margin trace is the experiment that would actually demonstrate it, and I haven't run that yet. Treat the mechanism paragraph as a hypothesis, not a finding.
The practical implication of all this: prompt-end metrics miss most of the phenomenon. If you measure JS at the prompt end and call it a day, you'll miss fragile models like Phi-4 that are confident at position one and unstable at position 400. The mature version of the measurement is multi-scale: prompt-end logits, plus longer-window text divergence, plus eventually per-step margin tracking during generation.
Traps, named and numbered
Let me consolidate. A naive stability probe has at least three failure modes, and they all show up concretely in the data above.
- Collapse. A degenerate model (canned responses, narrow manifold, over-quantized) scores as stable because outputs stop responding to input. Qwen 0.8B 4-bit is my example. Caught by measuring distance from a baseline system on identical prompts.
- Scaffold. Short-output score is dominated by a deterministic preamble. Qwen 4B and 9B, SmolLM3, DeepSeek-R1, Phi-4. Caught by pushing output length past the scaffold, or by stripping the scaffold before scoring.
- Confident-but-unstable. Phi-4. Top-1 probability 0.99999996 at prompt end, JS divergence
1.4 × 10⁻⁹on the bulk distribution, and yet 512-token semantic divergence of 0.160. Sharp logits do not mean a stable trajectory. Caught by multi-scale measurement, and eventually by per-step margin tracking.
Honestly the most useful output of this work, from a "will anyone cite this in a year" standpoint, is the named failure modes, not the specific numbers. The numbers will move as people run more prompts, more models, better tokenizer audits. The traps are what the field will keep hitting if it doesn't know to look for them.
A question I can't answer, that the lens suggests
There's an open question that fell out of this work that I don't know how to resolve, and I think someone else should chase it.
Compression has a well-studied static floor: how few bits of weight precision you need before you can't store the model. Rate-distortion bounds, work like TurboQuant and KIVI characterize this pretty well, and the floor is surprisingly low in many cases. Four bits is fine for a lot of things. Sometimes fewer.
The open question is whether there's a dynamical floor: how few bits before the behavior drifts, in the sense of moving off the response manifold in ways that wouldn't show up in a static quality benchmark but would show up in a sensitivity probe. And I'd expect that floor to depend on how sensitive the model was to begin with. A stable model (low Li-style per-layer stretching) should have more headroom to compress without drifting. A highly sensitive model should collapse earlier.
I ran a tiny Qwen 0.8B quant sweep that brushes up against this question, but I want to be careful not to over-read it. 0.8B is sensitive, it compressed fine by static metrics, and its behavior collapsed under 4-bit quantization on my probe. That's one data point, n = 9, one family. It's suggestive of "the dynamical floor and the static floor are not the same number," but it is not evidence for any particular relationship between sensitivity and that gap. I'm leaving the conjecture open, I'm not attempting to rescue it with my own data, and if it matters to anyone reading this, the experiment worth running is a proper sweep of stable-vs-sensitive models across several quantization levels, with drift-from-baseline measured in both directions.
Practitioner upshot
If you're shipping LLMs in a product, here's what I'd actually do with this work.
Stop evaluating on a single prompt, a single decode, a single metric. For a reliability claim, you need to test prompt neighborhoods. Take your canonical prompt, generate a handful of meaning-preserving perturbations (trailing space, line break, comma-to-semicolon, synonym swap), run all of them through the model, and report the range of responses. If the range is tight, great. If it's wide, you have a prompt that sits near a fragile boundary, and a small user-side typo or autocorrect will move your output.
For model comparison, report sensitivity ranges, not single-prompt scores. Cluster view. Two models whose means are 0.05 apart at n = 9 are not meaningfully different.
For output metrics, be paranoid about scaffolds. If your model emits a deterministic preamble, strip it before comparing, or run outputs long enough that the preamble is a minor fraction of what you're measuring. Compare answer spans, not raw outputs.
For decoding, use deterministic decode (do_sample=False) when you want the sensitivity signal clean. Use sampling separately for deployment. They answer different questions.
For quantization, lower perturbation divergence is not automatically a win. Pair it with drift from the unquantized baseline. If perturbation divergence dropped and baseline drift went up, you didn't buy stability, you bought collapse. Measure both.
One line I keep coming back to: prompting is operating a high-gain branching system. Test neighborhoods, not single prompts. It's the practitioner-sized version of the whole thesis.
Honest accounting
A few things I'd want a peer reviewer to hold me to.
Some of what follows has been flagged inline already. I'm pulling the limitations into one place so a skeptical reader can hold me to them.
Sample sizes are small. 9 prompt pairs per model cell in the main panel, 24 in the hardened Qwen wave. Enough to separate clusters (Qwen 4B vs 0.8B at p < 0.001), not enough to confidently order within a cluster (Qwen 4B vs 9B at p = 0.78). Specific model orderings are underclaimed by design. Please don't cite a ranked list out of this.
Scaffold vs recipe is a confound I can't untangle. The models with scaffolds are also the models with reasoning-oriented post-training. To separate "scaffold itself stabilizes" from "whatever recipe gave the model a scaffold also gave it other stabilizers," you'd need a matched pair: same base, one post-trained with a scaffold and one without. I don't have that. Someone at a lab that trains these things does.
Sentence-embedding distance is a proxy. Known failure modes: short outputs, scaffold dominance, register effects. I pair it with token-path diagnostics and logit-level metrics precisely because no single metric is safe. When metrics disagree, I report the disagreement rather than collapsing them into one score.
Failed experiments. A few models didn't run for boring tooling reasons. gpt-oss-20b hit an MXFP4/Triton driver mismatch on the SageMaker image. Nemotron Nano 9B v2 needed mamba-ssm in the container and my image didn't have it. Phi-4 mini had a Transformers version clash with its custom-code import. These are tooling misses, not stability findings. The panel is smaller than I'd like, and it's not because those models are interesting or boring, it's because they didn't run.
Closing
This is a measurement proposal and a lens, not a benchmark paper. The finding I'd most want to survive is: stability is a property of a system, not a score. Low output divergence on a single probe is not automatically stability. It could be collapse. It could be a scaffold dominating your metric. It could be a prompt-end measurement missing a low-margin boundary crossing 400 tokens into the generation. Each of those failure modes shows up concretely in the data. All of them would have looked like "this model is stable" on a naive benchmark.
The chaos lens, from the first post, is what organizes this. LLMs are hybrid sequential systems. Continuous activations that stretch, feeding a discrete branching process that can flip at low-margin boundaries. Small input changes can either be absorbed (bulk moves a little, top-1 holds) or amplified (top-1 flips, autoregression runs with a different prefix, output diverges). Whether a given input/model pair does one or the other depends on the prompt, the model's stretching rate, the density of low-margin decisions in the generation, and the metric you're using to look at the output.
The next step after this post, which I wasn't sure was tractable when I wrote this one, is per-step tracking of where the flips actually happen and whether they're causally localizable inside the forward pass. I ended up running that experiment. Low top-1 margin and high JS divergence against the other run catch the flip cleanly at the moment it commits (roughly 0.95 and 0.88 AUROC on an 8-model panel), but they don't do nearly as well one token earlier, so "predict the branch from the prompt" is harder than "detect it when it happens." And by patching residual-stream activations from the unedited run into the edited one, you can cause the model to pick the original token. Across 82 cases on 8 open models, every case has at least one position where a patch fully rescues, and they cluster into a small number of recognizable shapes. That's Part 3.
If you're doing LLM evaluation and any of this feels relevant, I'd love to hear about it. There's a lot more here than one person can run.