Nearby Prompts, Distant Trajectories
Spin up a local LLM on your device and set everything to be deterministic: zero temperature, no sampling, batch size 1, etc. Then type any random sentence and it will output the same response. LLMs by themselves are inherently deterministic. This has become fuzzy over the years. We add sampling and temperature for variance and we batch requests to handle more users, so don't expect this to work on ChatGPT. But back to our experiment. If you then add just a single extra space somewhere in your deterministic query, you get a different result, maybe! There are a lot of parameters in an AI model. Sometimes the littlest things have no effect, sometimes they can flip the meaning of the response completely. What if the first token generated had logits for yes=4.200 and no=4.198 then a slight disturbance in the forward passes resulted in yes=4.200 and no=4.203. An answer starting with Yes is now a No. (to be fair this would be quite an uncertain LLM)
That something has a name in physics: sensitive dependence on initial conditions. The butterfly effect is the line everyone knows, it's a synonym for randomness, or cosmic bad luck, or the vague idea that small things sometimes matter. More technically it's a specific property of a specific kind of system: deterministic amplification of small differences. Given two almost identical starting points, the trajectories peel apart at a rate you can measure. What if that extra space or an errant punctuation gets amplified in LLM generations? What if the entire response changes its meaning?
This post lays out the framing carefully. What chaos actually is, why it isn't randomness, why neural networks sit in the neighborhood of chaotic systems, and what "state" even means in a language model.
This is the first of three posts, just the initial conditions. The second is the experiment, where I move on to real models and get into what moves and what doesn't. The third goes inside the network: if small prompt changes push the model onto a different branch, can we find the exact position where the branch happens, and patch it to undo the flip? Both are being rewritten and will go up shortly.
What I am and am not claiming
Let me get the obvious objections out of the way first, because I am going to play a bit loose with the rules.
I am not claiming LLMs are chaotic in the formal sense. Classical chaos requires things LLMs don't have: an infinitely iterated map, the ability to take perturbations to zero, asymptotic time. LLMs have finite depth, finite context, and a discrete token space. You cannot (cleanly) take the limit needed for a Lyapunov exponent.
I am not claiming bigger models are more stable. I am not claiming reasoning models are more stable. I am not claiming that lower divergence is better. Stability is just one property, it's not a score. A model that outputs "the the the the" forever, regardless of the prompt, is extremely stable. But it's not very useful!
I am not claiming that sentence-embedding cosine distance is ground truth for "how much did the output change." It's just a proxy for purposes here.
What I am claiming is something narrower. At inference time, an LLM is what I'd call a hybrid sequential system. Continuous activations flowing through a stack of layers, feeding a discrete branching process at the output. Small changes in the input can do one of two things. They can move the next-token distribution a little (a bulk shift), or they can flip the argmax onto a different branch (a boundary crossing). Once a branch flips autoregression takes over and the rest of the generation runs on a different prefix. The system compounds. Sound familiar?
Whether that compounding is big enough to care about depends on the model, the prompt, and the metric. That's an empirical question and it's the one the rest of this work tries to answer.
Chaos isn't randomness
It's worth spending time on the physics, because the word "chaos" is doing a lot of work in this post, and the only way to use it fairly is to remember what it originally means.
Chaos, in the technical sense, is deterministic amplification of small differences. Take two pendulums. Same mass/length/gravity and same initial push, except one is released at an angle that's off by half a degree. In a simple single pendulum, that half-degree difference stays small forever. The two pendulums track each other. But in a double pendulum, where the second arm is attached to the first and free to swing, that half-degree difference grows. Within a few seconds the two pendulums are in completely different places. Not because of noise or a random kick. Because the equations of motion, running deterministically, take the tiny gap you started with and stretch it.
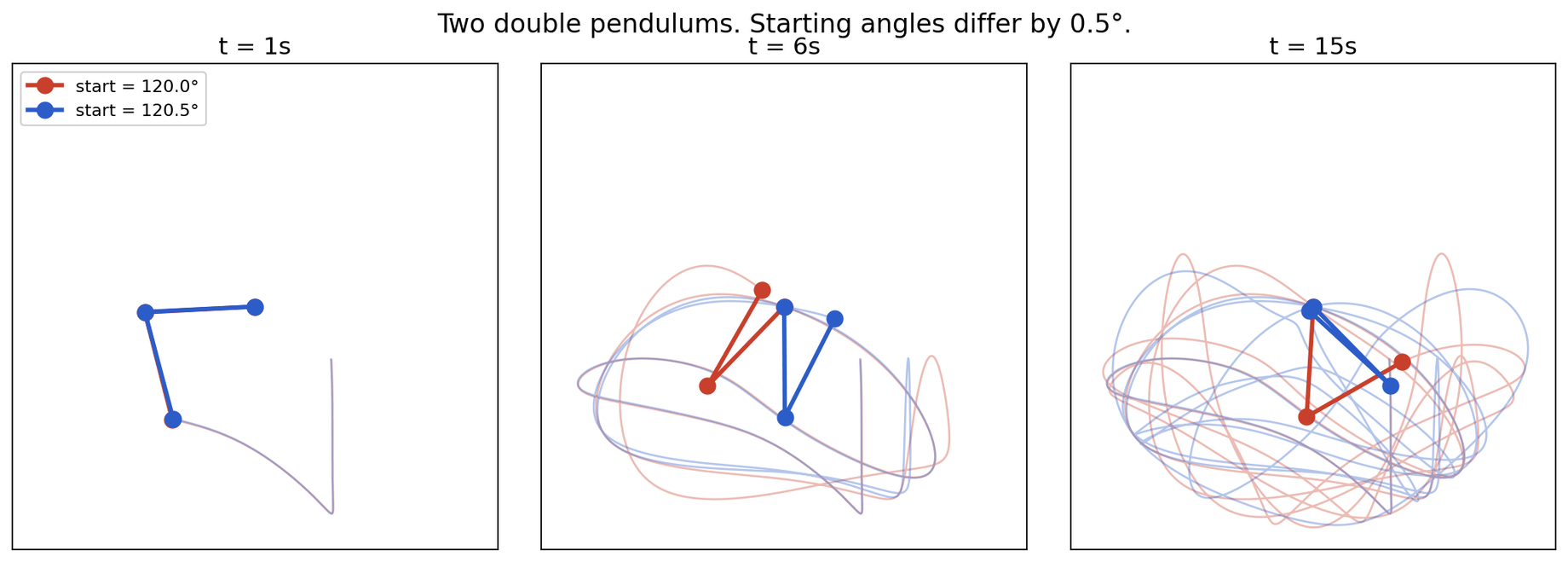
If you calculate the system's exact path over time using its laws of motion, you get a number that measures how fast neighboring trajectories split apart: the Lyapunov exponent (λ). If two trajectories start a distance δ(0) apart, their separation at time t grows roughly like |δ(t)| ≈ |δ(0)| · e^(λt). If the exponent is positive, the gap grows exponentially. If zero, the system is on the edge. If negative, the gap shrinks, and small differences get forgotten.
The Lyapunov exponent is the formal content of "the butterfly effect." It's a time-averaged local stretching rate. It's what lets us say something precise about how fast a weather forecast degrades or how predictable a pool shot is after the sixth collision (answer: not very).
The cleanest teaching example of this is the logistic map.
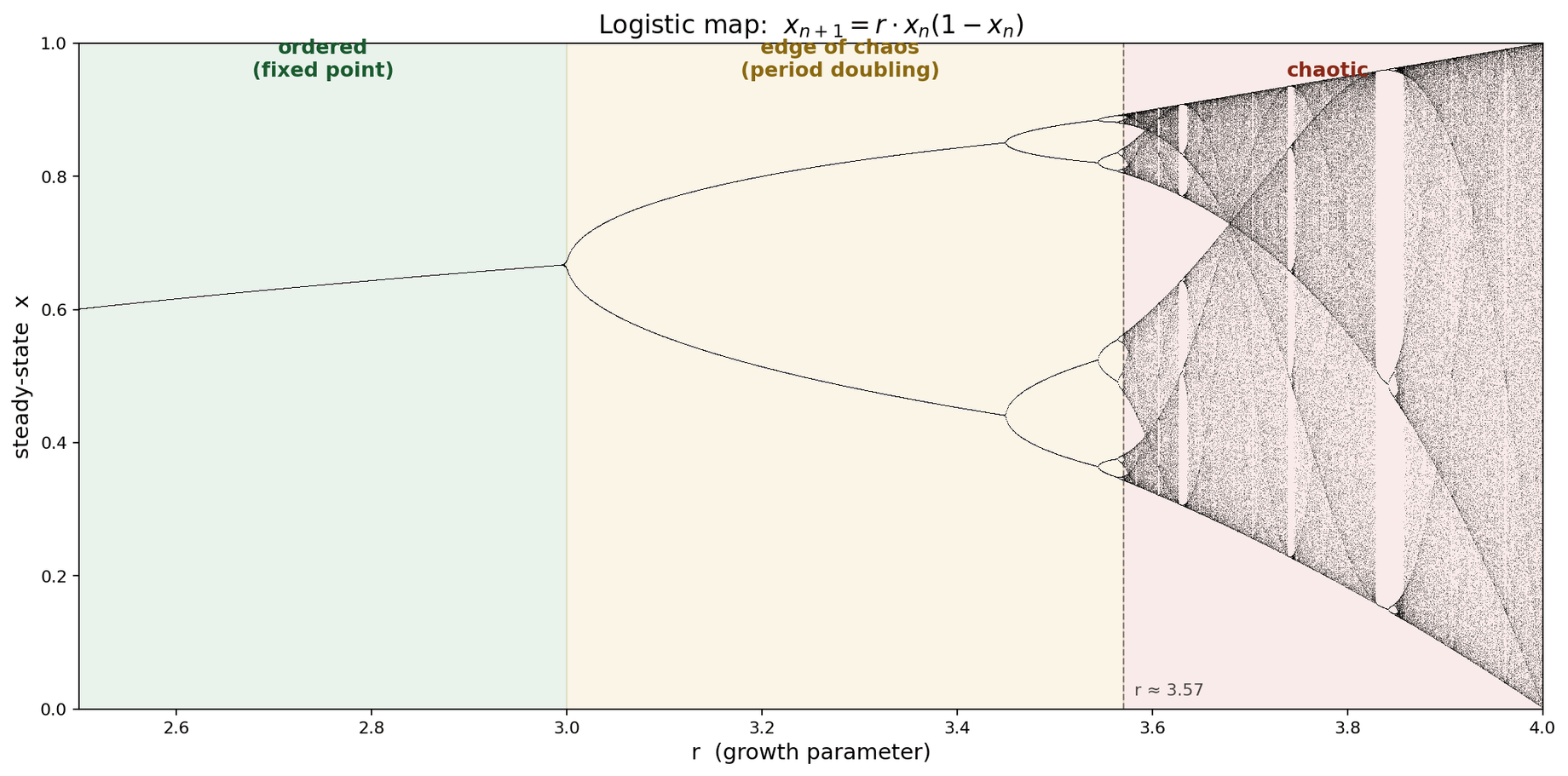
The chart above is a bifurcation diagram, and it is possibly the most misread image in applied math. The x-axis is r, the knob. It is not time. Each vertical slice is an independent experiment: fix r, iterate for thousands of steps, throw away the transient, plot every value the system ends up visiting. For low r the system settles on one value, so the slice is one dot. Turn r up past about 3, and the system can't hold onto a single value anymore. It starts alternating between two values forever. Period two. Turn it up more, four values. Eight. Sixteen. The splits accelerate, pile up, and by r around 3.57 the column is a smear. The system never repeats.
The reason this chart is a canonical piece of applied math isn't because dripping faucets are interesting, though they happen to be in this same universality class. It's because Feigenbaum showed in 1978 that a huge class of one-dimensional folding maps follows this same period-doubling route to chaos, with the same constant in front of it. Fluid onset in certain convection regimes. Some laser intensities. Some electronic oscillators. Heart arrhythmias, at some knob settings. All with this bifurcation cascade. The logistic map is representative of a broad class.
Trained neural networks sit near the chaos boundary
So where do LLMs come in? The claim is not that I have proven LLMs are chaotic, but the family of systems LLMs belong to is already known to live in a narrow band between ordered and chaotic regimes, because that happens to be where training is most effective.
Langton, 1990, "Computation at the Edge of Chaos." Cellular automata. Langton showed that interesting computation, meaning the ability to propagate signals over long distances and remember things, happens in a narrow parameter band between fully ordered (everything freezes) and fully chaotic (signals decorrelate to noise).
Poole et al. 2016, Schoenholz et al. 2017. Deep feedforward networks. They show that at random initialization signals propagating through a deep network either shrink to zero (ordered regime, gradient vanishes) or blow up (chaotic regime, gradient explodes). Initialization near the edge between those regimes is what mean-field theory predicts will train well, and empirically does in vanilla feedforward stacks. You see modern techniques that focus on this such as residual streams, normalization, and better optimizers, but the underlying premise goes back to our idea that the "edge of chaos" is a specific surface in hyperparameter space. The closer you sit to this space the more reliably signals and gradients propagate.
I have to be careful with how I use this. The edge-of-chaos literature is about signal propagation during training in feedforward networks, not about prompt sensitivity during greedy decoding of a trained autoregressive LLM. One does not automatically imply the other. The most I'd claim is that the two phenomena share mathematical ancestry (stretching, gradient dynamics, sensitive dependence), and the vocabulary from one is disciplined enough to be useful when discussing the other, without me claiming they're identical.
That said to say: the conditions under which deep networks are trainable overlap with the conditions the signal-propagation literature calls edge-of-chaos, and that's the vocabulary I'm going to reach for. Chaos theory supplies disciplined vocabulary for describing sensitivity in a system that discretizes stretched continuous states into branch points.
That's what buys me permission to use chaos vocabulary for LLMs at all. The real question isn't "are LLMs chaotic." It's narrower: "for a given trained LLM at inference time, on this input, how much does the response function amplify a small change, and does that vary in ways we can measure?"
So, is an LLM a dynamical system?
Let's think.
A dynamical system has state. LLMs have state: per-layer residual activations, logits, the prefix of tokens generated so far, the KV cache that backs attention over that prefix. That's a lot of state.
A dynamical system has iteration. LLMs iterate: each forward pass produces a token, the token gets appended to the prefix, the prefix conditions the next forward pass. That's autoregression. The same function applied repeatedly, with the output of step n fed back as input to step n+1. The logistic map also has this shape. So does every other iterated map in the dynamical systems textbook.
A dynamical system is typically deterministic, at least when you want to analyze it. LLMs are deterministic under argmax decoding: do_sample=False in the HuggingFace transformers API, which picks the highest-logit token at every step. Run the same prompt through the same weights twice with argmax decode, and you get byte-identical output up to GPU kernel nondeterminism. As a quick example: because bf16 is non-associative, changing the batch size can change the reduction order of a sum enough to flip the argmax on a low-margin token. So I run every generation at batch size one. The remaining kernel-level nondeterminism is tiny and not the source of the effects I'm measuring.
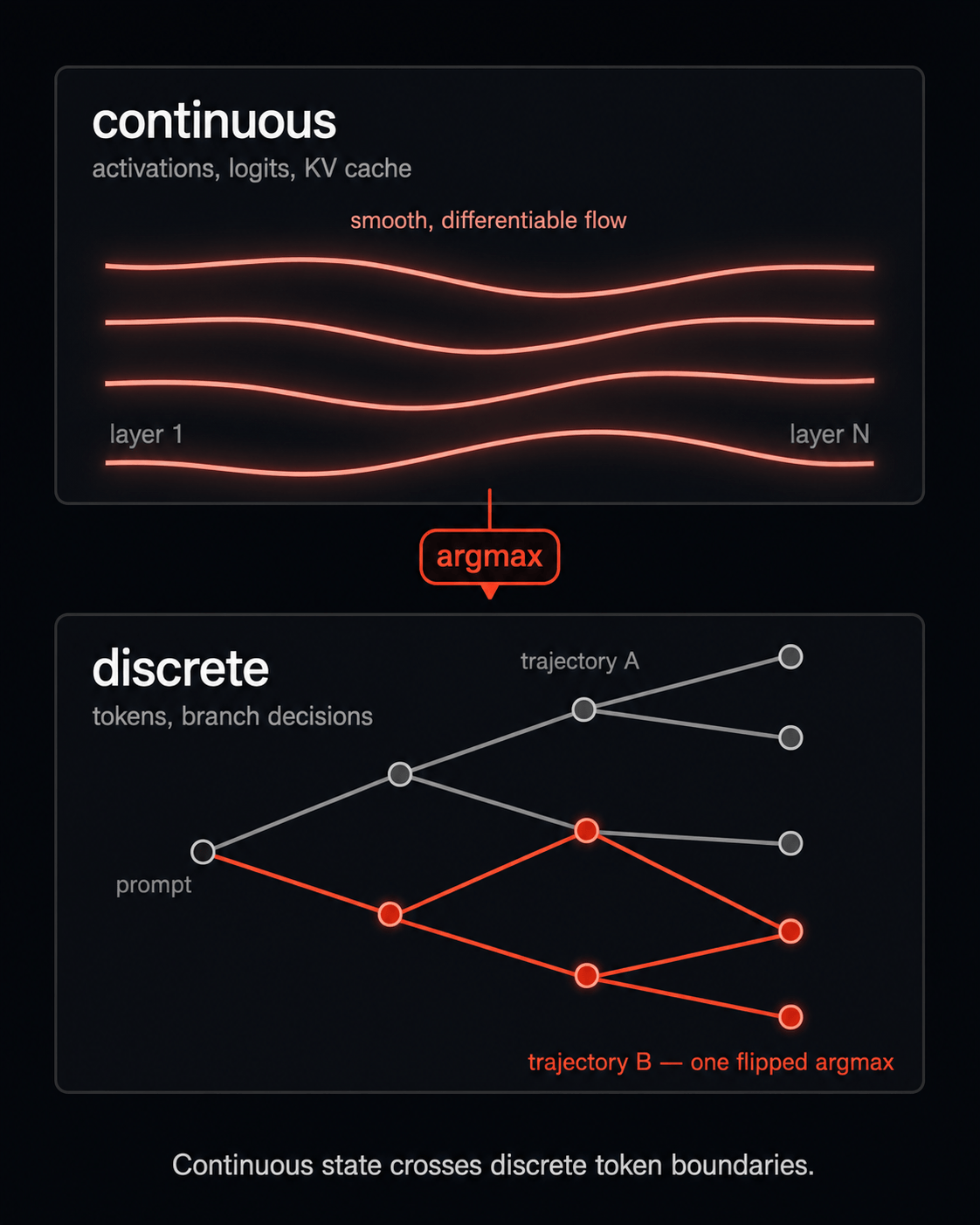
A dynamical system can amplify small input differences. LLMs can too, at least sometimes, which is what the experiment in part two sets out to measure. The example from the top of this post is a real datapoint, and here it is with the specifics: The model is OLMo-3 7B (open weights, so the run reproduces). Prompt A: "write a concise Python palindrome function." Prompt B: the exact same string, with a single trailing space after the period. Again conditions are: Argmax decode, same weights, same seed, and no temperature.
Prompt A gives a clean utility function with a docstring. Prompt B gives a chatty conversational preamble followed by a one-liner implementation. Two different answers from one trailing space character in the prompt. That's the kind of thing the rest of this work asks: how often, in which models, and under what conditions. The answer is more structured than "any byte flips the model," but it's also much less boring than "they're basically the same."
So on the checklist, an LLM at inference has state, has iteration, is deterministic, and can amplify small input changes. Ok so far it fits, we can now pivot to the magnitude of the effect.
Another hedge before I continue. Classical chaos wants to take input perturbations to zero, because the math is an asymptotic statement about infinitesimal separations. Token space is discrete. The smallest perturbation in token space is one token. You can't take the limit. So anything I do here is going to be a finite-perturbation probe of a discretized system, so we can not precisely compute a classical Lyapunov exponent at the text level.
An interactive detour
If the stretching-rate argument above felt abstract, it might help to actually see a ripple propagate through something that sort of looks like a tiny network. Just a fun example, it is not a real language model or even a real neural net. It's a few rows of cells where each cell's next state depends on its current state and its neighbors, and you can click to perturb one cell and watch the disturbance spread.
The purpose is just building intuition: the same local rule can either swallow a disturbance or amplify it depending on the regime. Click around a bit.
What this shows you isn't specific to language models. It's showing you the condition for chaos: a local rule that when iterated over state can take a tiny perturbation and not let it dissipate. The logistic map has this property at high r. A double pendulum has it at moderate-to-high energies. A signal-propagation-tuned neural net has it in the regime where it's trainable.
Temperature and Sampling
Temperature is a parameter that controls sampling. You have a fixed next-token distribution, computed by the model for a given input. Temperature T rescales the logits before the softmax: p_i ∝ exp(logit_i / T). As T goes to zero, the distribution collapses to the argmax (all mass on the max-logit token). At T = 1, you get the raw distribution. As T grows, the distribution flattens toward uniform. Temperature is how peaked or flat the distribution is, when you draw from it.
Sensitivity is a different question. Sensitivity asks: when the input changes a little, how much does the distribution itself move? Before you sample anything. You have a distribution given the original prompt, and a distribution given the perturbed prompt, and the question is the distance between those two distributions. These are orthogonal axes. You can have zero sampling noise (temperature zero) and still see the output move a lot. You can also have high sampling noise and a rock-solid distribution.
Here's the 2x2 that unsticks it for me. Same prompt at temperature zero gives byte-identical output, which is just determinism. Same prompt above temperature zero gives different draws from the same underlying distribution, which is sampling noise and not very interesting. A different prompt above temperature zero changes both the draws and the distribution at once, so you can't tell the two effects apart; that cell is confounded and useless. The cell that matters is a different prompt at temperature zero: the sampling step is gone, so any movement in the output is the response function of the model itself. The distribution moved, and nothing else could have moved it. That's the clean probe.
That last cell, different prompt at temperature zero, is what the rest of this project measures. The whole experimental apparatus is built around stripping out sampling so that what's left is the model's functional response to input.
One line, because this is the pedagogical linchpin: temperature samples from a distribution. Sensitivity asks how far the distribution moved. If you only remember one thing from this post, I'd take that.
Meaning-preserving perturbations
There's a subtlety here that matters for how you interpret any of the results. When a prompt perturbation produces a different output, that's not necessarily the model making a mistake. A double pendulum isn't wrong when it lands somewhere different after a half-degree nudge. The physics is working as advertised. The pendulum is expressing sensitive dependence, which is a property of the system, not a bug.
Same bar for LLMs. If I ask "recommend a book like Dune" and the model says Foundation, and I ask "recommend a book like Dune " (with a trailing space) and the model says The Left Hand of Darkness, both answers are defensible recommendations to a human reader. Neither is a hallucination. The model picked a different basin of its response manifold.
It also tells me what the right quantity to measure is. Not just "how much did the output change," but output change per unit of meaning-preserving input change. If you stick the word "NOT" in front of the prompt, of course the output moves. The meaning changed and the model is working correctly. The interesting case is when the meaning didn't change, and the output moved anyway. That's where the chaos lens starts to pay off.

"Meaning-preserving" is not a robust term here but it should help differentiate. A synonym swap isn't perfectly meaning-equivalent, a paraphrase really does shift nuance, and whether ending a sentence in two periods instead of one carries any semantic load is a question for a linguist. The perturbations I use in the second post aren't claimed to be semantically identical to the original. They're claimed to be the kind of change a human reader wouldn't flag as asking a different question. It's a soft version of meaning preservation but the right one for the probe: changes that feel invisible yet still sometimes move the output.
State, and what Li et al. actually measured
Let's pause again because I am not the first person to try to put dynamical systems vocabulary on an LLM, and there's a specific paper that did the rigorous version of this inside activation space while I was doing the broad version of it at the output-text level. These are complementary though do focus on different abstraction layers.
The paper is Li et al. 2025, quasi-Lyapunov analysis on a Qwen2 model. They call it quasi-Lyapunov because classical Lyapunov needs infinite iteration of a fixed map, and LLMs have finite depth. The finite-depth analog is a per-layer hidden-state growth ratio: take the residual stream at layer n, and ask how much bigger it is by layer n+1. Average that over layers, and you get a per-layer stretching rate. Which is: the time-averaged local stretching rate, but with "time" replaced by "depth." Think of the model weights being millions (billions?) of strings laid out in the physical world, linking together all the layers. Drop a weight on earlier layers, or pluck them, how does that propagate?
The number they get is about 1.32x per layer in the first ten layers, falling to roughly 1.08x in later layers. Compounded over depth, that's still two orders of magnitude of amplification. A tiny perturbation in the input embedding becomes a meaningful perturbation in the final residual stream.
The sharper framing, though, is their residual-stream decomposition at the final layer. Decomposing the final residual norm by source: MLP contributions account for 55.8%, attention contributions for 44.2%, and the initial input embedding for 0.0009%. Ok that feels pretty chaotic: we perturb the 0.0009% and watch the rest of the stream move. Almost everything that ends up in the output is transformations done inside the network. The input is a tiny seed and the network amplifies it.
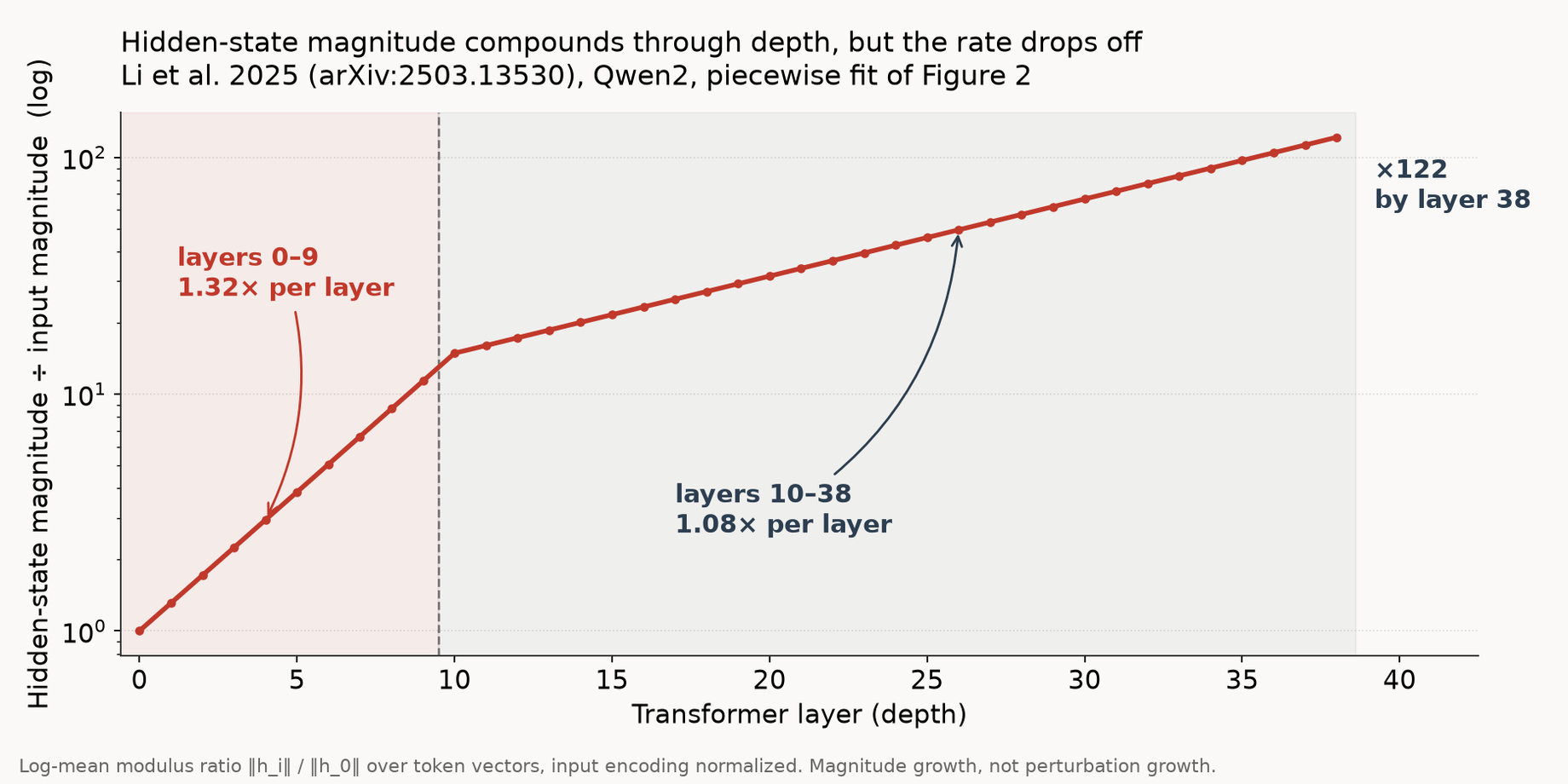
The paper has one more result I want to mention. They compute the QLE for perturbations introduced at each layer and plot it as a heatmap. Shallow layers mostly converge: perturb them and the difference gets squeezed back out. Deep layers diverge, and strongly. So the chaotic behavior isn't spread evenly through the stack, it concentrates in the later layers. That matters for the third post, which goes looking for the specific position where a branch gets committed.
Here's the demo I built while I was trying to internalize this. It's a toy visualization of a perturbation propagating through a stack of "layers" with a stretching rate you can adjust. Not real activations, but the right shape.
Li et al. ran one model. They defined a token-level iterative exponent in their paper but never actually computed it, and they never compared across models. That gap is exactly where my experiments sit. I'm not doing the rigorous activation-space math they did. I'm doing the shadow at the output level, across a zoo of models, to ask which models are more sensitive and where the failure modes of the measurement lie.
Also worth naming: Geshkovski et al. 2023 treat attention layers as interacting-particle dynamics, tokens as particles, attention as the interaction force. Tomihari and Karakida 2025 do a Jacobian-Lyapunov analysis specifically for self-attention.
Consolidating this all
An LLM at inference time is a hybrid system. Continuous activations flowing through a stack of transformer layers, producing a next-token distribution. A discrete selection (argmax, or sampling) picks one token from that distribution. The chosen token appends to the prefix. The prefix is the input to the next forward pass. Repeat.
The continuous part stretches. Li et al. quantify the stretching at roughly 1.32x per layer in activation space for the Qwen2 model they analyze. The stretching means that a small perturbation in the input, carried through the stack, becomes a meaningful perturbation in the logits at the output.
Then what? The discrete part branches. At the top-1 selection step, a perturbation can do one of two things. If the perturbation is small relative to the margin between top-1 and top-2 logits, the argmax stays the same, no branching and same output token. If the perturbation is large relative to the margin, the argmax flips and the branch changes. Now, once a branch flips the prefix for every subsequent forward pass is different and the entire downstream trajectory is different. That's where we can see things begin to compound.
So the stability of a generation depends on two things. One: how much the input perturbation gets amplified through the continuous stretching. Two: how many thin boundaries the generation passes through, where a small logit perturbation is enough to flip the top-1. The first is a property of the weights (Li et al.'s per-layer growth ratio). The second is a property of the weights and the prompt, because whether a given step sits on a low-margin boundary depends on what the model is trying to do at that step.
This is why I don't want to give you a single scalar "how chaotic is this LLM" number. The system doesn't have one. It has a stretching rate and it has a boundary-density pattern over generation. A later post goes one step further and asks whether the boundary flip is causally localizable in the forward pass: given a prompt pair that branches, is there a specific residual-stream position where the flip is already committed, such that patching it from the unedited run into the edited run puts the model back on the original trajectory?

What I did next
Given the lens above, the question I wanted to answer is: across a reasonable slice of publicly available models, how sensitive are they to meaning-preserving prompt perturbations?
I collected a varied set of open source models, spun them up on my own hardware and started running the experiments. To be continued.