Where the Branch Commits
This is the third of three posts. The first, Nearby Prompts, Distant Trajectories, is the framing: chaos vocabulary for LLMs at inference time, and the claim that greedy decoding is a hybrid system where continuous state stretches and discrete output branches. The second, Measuring LLM Sensitivity, is the 21-model probe and the traps the measurement lays for you. Here, we dive into the model itself.
The question: when a tiny prompt edit changes one or more output tokens, where in the forward pass is that flip actually committed? Sitting at the edited token? Accumulating silently in the shared generated prefix before the visible split? Or is the model overwriting its own context late, with the prompt edit acting as a long-range trigger?
Short version. Across 82 token-certified prompt pairs on eight open-weight models, the branch flip is usually localizable to a specific residual-stream position: patching the unedited run's activation at that one position is enough to restore the original token. Every case has at least one such position, and they cluster into three recognizable shapes. The most interesting result is a negative one. If the model were really "deciding late," running mostly in parallel and only committing to the branch just before it emits a different token, you'd expect cases where patches only work at the end, near the branch, and earlier patches do nothing. Zero of 82 cases look like that. The branch is already latent somewhere earlier in the pass, in every case I measured.
What activation patching does
Run prompt A through the model and record, at every layer and position, the residual-stream activation. Run the perturbed prompt A', but at one specific (position, layer) swap A's recorded activation in for A''s natural one. Let the forward pass continue. Look at the branch-step logits: did the patched run pick A's original token? If it did, the information needed to produce A's continuation was sitting at that (position, layer), enough that reinserting it flips the argmax back. The token emitted at each step is just the argmax over the final-layer logits, so sweeping the patch across layers tells us how early in the stack the decision is already recoverable.
I report what I call the rescue_fraction, where a score of 1.0 means the patch fully restored the original logit gap and 0.0 means it did nothing. I test patches at the first prompt token where A and A' differ (prompt-LCP), sampled positions from the shared prompt region (a null-hypothesis control), any tokens both runs generated identically before the branch (generated-prefix), and the final position before the branch. At each position I sweep every layer and record the best-layer rescue. "Prompt-LCP rescues" means some layer there produces full rescue (an existence claim).
Three shapes keep showing up
In the 82 token-certified prompt pairs I mentioned earlier, I used Qwen 3.5 at 0.8B, 2B, 4B, and 9B, and Gemma 4 at E2B and E4B, base and instruct. Greedy decode, deterministic, bfloat16 on CUDA, pinned revisions. A decision rule I wrote down after looking at the first 42 cases, then applied unchanged to a reserved 40-case wave:
- If the prompt-LCP position achieves full rescue at any layer, call it boundary rescue.
- Otherwise, if the edit sits at token 0 (no shared prompt prefix), call it tokenization-shift immediate.
- Otherwise, call it generated-prefix rescue after silent divergence.
Applied to the full panel, the split is 41 / 14 / 27.
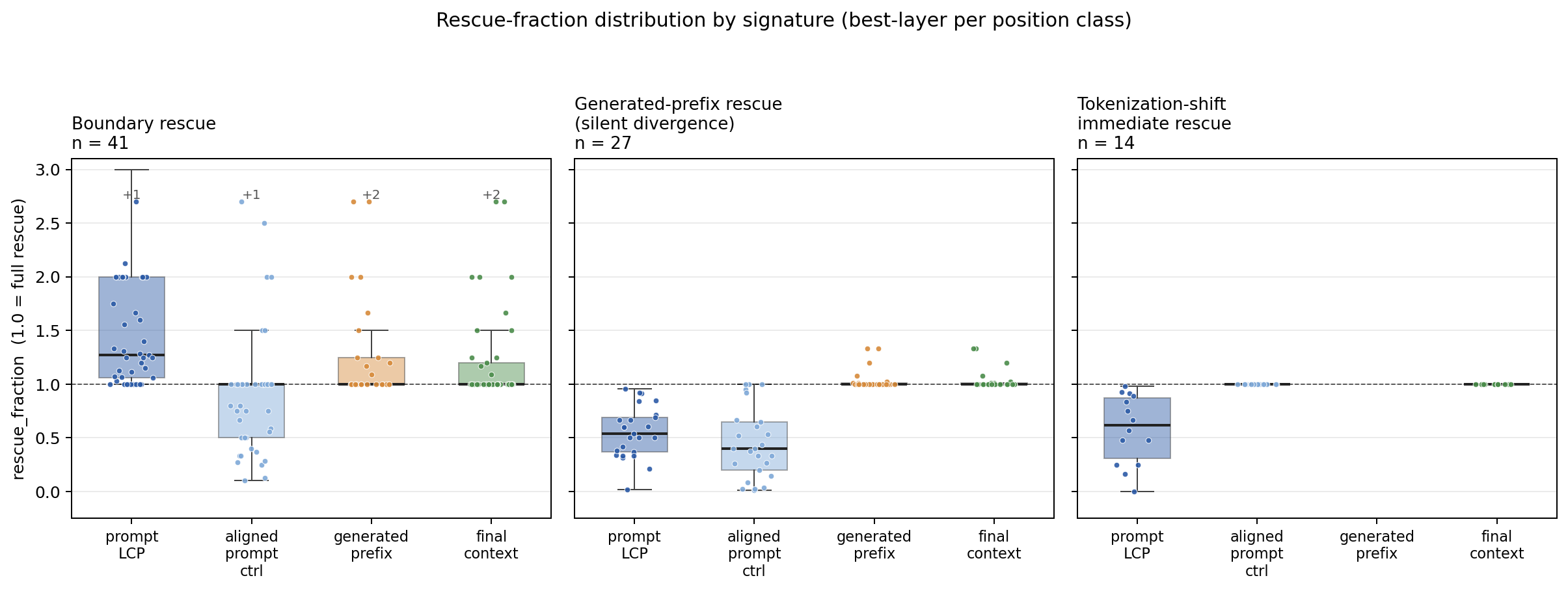
Boundary rescue (41 cases) is what you'd predict if the prompt edit's effect is local. The model sees a different token at position k; that difference carries forward, shifts the branch-step logits, flips the argmax. Patching the unedited activation back in at that one prompt token undoes the flip.
Generated-prefix rescue after silent divergence (27 cases) is the more interesting shape. Both runs emit the same visible tokens for a while, then diverge. Patching prompt-LCP is only partial (median 0.54). But some position in the shared generated prefix is fully sufficient. Read that carefully: both runs emitted the same token at that position, yet their residual activations there differ enough that swapping one for the other changes what comes out 20 or 30 tokens later. The edit has already perturbed internal state before it became visible. This matches the dynamical picture from Post 1, where continuous state is stretching while discrete output lags, until a low-margin decision crosses into a different basin.
Tokenization-shift immediate (14 cases) is the degenerate shape. The edit is at token 0, so "first differing prompt token" and "last prompt position" collapse. I keep it separate because the geometry is different when every prompt token differs.
The striking part is the missing fourth category. We never see a case where the prompt-side patches fail, the shared-prefix patches fail, and only a patch right before the branch token works. That would be the shape you'd expect if the model really merged the two runs and then made a fresh choice at the visible fork. Instead, every case has an earlier handle: either the edited prompt token itself, or some hidden state in the shared generated prefix. The fork is not created at the fork; it is carried into it.
What the signatures do and don't say
Activation patching has an important limitation: it tells you where a state is sufficient to change the output, not where the model originally did the computation. If swapping in activation X restores token A, that means X carries a usable handle on token A. It does not mean X is the whole circuit, or even the place where the relevant computation began.
With that caveat, the result still says something useful. These branches are not purely last-second events. If they were, patching the edited prompt token would not rescue 41 cases, and patching the shared generated prefix would not rescue another 27. In those cases, the information needed to recover A's token is already present before the visible flip.
The silent-divergence cases are the cleanest match to the dynamical picture from Post 1. The text stream stays identical, but the hidden state has already started to separate. Continuous state moves first; discrete tokens lag behind.
I am not claiming the three signatures are three distinct circuits. They are three shapes in this particular patching experiment. A different patch grid, model family, or edit distribution might expose different shapes. The taxonomy is operational: it says what kind of intervention works, not what mechanism must exist underneath.
A natural next question: can you see the branch coming before it happens? If you only watch the logits, the model's final, vocab-level prediction, the answer is mostly no until the last moment. Right at the branch step the signal is obvious: the gap between the top two candidate tokens collapses, the two runs' distributions disagree sharply. But one token earlier, those same signals are barely above a coin flip. From the final-layer view, the branch is invisible until it's nearly here.
That answer changes if you stop looking only at the final layer. Logits are a single number squeezed out of a much richer internal state we have full access to when we run the model ourselves. So I ran a follow-up with eight models, 915 prompt pairs, and a small classifier trained on the difference between the two runs' hidden states at matched generation steps. The classifier scores around 0.76 (on a scale where 0.5 is a coin flip and 1.0 is perfect) at one token before the visible flip, and still around 0.73 at ten tokens before. The same classifier built on logit-level features only is barely above chance. The flip is already brewing inside the network several tokens ahead; the logits just haven't caught up yet.
Two honest caveats. The classifier compares two runs at once (clean and edited) to spot which step is approaching a known branch. It is not a single-run alarm system you could attach to one prompt and ask "is this about to flip?" And the window where it works is narrow: roughly ten tokens, not a hundred. Inside those limits, this is the cleanest match to the dynamical-systems story from Post 1. The continuous state separates first while the visible token catches up later. And the gap between them is wide enough to read off, if you look in the right place.
A tool that fell out of this
I packaged all of this into something I'm calling BranchTrace. The user story:
You changed a prompt, a template, a model version, or a RAG input. An eval that used to pass now fails. BranchTrace finds the first generated token where the old and new outputs split, replays both futures, and tells you whether a small intervention at a natural position (the prompt edit itself, or somewhere in the shared runway) flips the result back. If so, you've localized the regression and you can reason about a fix.
I built an interactive lab where you can poke at three example cases: pick a case, see the prompt diff, the shared runway, the branch-step top-k, and the per-position patch scores. The default case has both runs writing "Monitoring ensures that work meets" and then disagreeing on whether the next word is "established" or "agreed." Copy the same-position hidden state from the unedited run, and the edited run flips back to "established."
→ Open the interactive branch lab
The behavioral parts of this work fine against closed APIs. You only need prompts, outputs, and logprobs to find the divergent token and replay. The patching evidence is the part that needs local weights.
BranchTrace gets its own post soon. For now: if you ship prompts to production and "the model regressed" debugging conversations sound familiar, that's the gap I think this fills.
Where this lands
The overall story, if you've read all three: at inference time, an LLM's greedy output is locally stable until it isn't, and when it isn't, the flip is usually sitting at a specific, findable place in the residual stream. Sometimes it's the prompt edit itself. Sometimes the information has already spread into the shared generated runway by the time the flip shows, and a patch there is the handle. Both shapes appear; neither is rare. The naive late-overwrite story doesn't describe any case I tested. The chaos lens wasn't strictly necessary to find this, but it's the mental model that makes it make sense: continuous stretching feeding discrete branching, with low-margin decisions as the point of vulnerability.
If any of this lands for you, I'd love to hear about it. My inbox is on the homepage. The obvious next experiments for anyone with compute: donor-specificity across more models, and a proper held-out panel where the rule is written down before the patch CSVs exist.
Back to Part 1: the framing or Part 2: the experiment.